3. Configurations and Zone Files
3.1. Introduction
BIND 9 uses a single configuration file called named.conf. which is typically located in either /etc/namedb or /usr/local/etc/namedb.
Depending on the functionality of the system, one or more zone files is required.
The samples given throughout this and subsequent chapters use a standard base
format for both the named.conf and the zone files for example.com. The
intent is for the reader to see the evolution from a common base as features
are added or removed.
3.1.1. named.conf Base File
This file illustrates the typical format and layout style used for
named.conf and provides a basic logging service, which may be extended
as required by the user.
// base named.conf file
// Recommended that you always maintain a change log in this file as shown here
// options clause defining the server-wide properties
options {
// all relative paths use this directory as a base
directory "/var";
// version statement for security to avoid hacking known weaknesses
// if the real version number is revealed
version "not currently available";
};
// logging clause
// log to /var/log/named/example.log all events from info UP in severity (no debug)
// uses 3 files in rotation swaps files when size reaches 250K
// failure messages that occur before logging is established are
// in syslog (/var/log/messages)
//
logging {
channel example_log {
// uses a relative path name and the directory statement to
// expand to /var/log/named/example.log
file "log/named/example.log" versions 3 size 250k;
// only log info and up messages - all others discarded
severity info;
};
category default {
example_log;
};
};
The logging and options blocks
and category, channel,
directory, file, and severity
statements are all described further in the appropriate sections of this ARM.
3.1.2. example.com base zone file
The following is a complete zone file for the domain example.com, which illustrates a number of common features. Comments in the file explain these features where appropriate. Zone files consist of Resource Records (RR), which describe the zone’s characteristics or properties.
1; base zone file for example.com
2$TTL 2d ; default TTL for zone
3$ORIGIN example.com. ; base domain-name
4; Start of Authority RR defining the key characteristics of the zone (domain)
5@ IN SOA ns1.example.com. hostmaster.example.com. (
6 2003080800 ; serial number
7 12h ; refresh
8 15m ; update retry
9 3w ; expiry
10 2h ; minimum
11 )
12; name server RR for the domain
13 IN NS ns1.example.com.
14; the second name server is external to this zone (domain)
15 IN NS ns2.example.net.
16; mail server RRs for the zone (domain)
17 3w IN MX 10 mail.example.com.
18; the second mail servers is external to the zone (domain)
19 IN MX 20 mail.example.net.
20; domain hosts includes NS and MX records defined above
21; plus any others required
22; for instance a user query for the A RR of joe.example.com will
23; return the IPv4 address 192.168.254.6 from this zone file
24ns1 IN A 192.168.254.2
25mail IN A 192.168.254.4
26joe IN A 192.168.254.6
27www IN A 192.168.254.7
28; aliases ftp (ftp server) to an external domain
29ftp IN CNAME ftp.example.net.
This type of zone file is frequently referred to as a forward-mapped zone file, since it maps domain names to some other value, while a reverse-mapped zone file maps an IP address to a domain name. The zone file is called example.com for no good reason except that it is the domain name of the zone it describes; as always, users are free to use whatever file-naming convention is appropriate to their needs.
3.1.3. Other Zone Files
Depending on the configuration additional zone files may or should be present. Their format and functionality are briefly described here.
3.1.4. localhost Zone File
All end-user systems are shipped with a hosts file (usually located in
/etc). This file is normally configured to map the name localhost (the name
used by applications when they run locally) to the loopback address. It is
argued, reasonably, that a forward-mapped zone file for localhost is
therefore not strictly required. This manual does use the BIND 9 distribution
file localhost-forward.db (normally in /etc/namedb/master or
/usr/local/etc/namedb/master) in all configuration samples for the following
reasons:
Many users elect to delete the
hostsfile for security reasons (it is a potential target of serious domain name redirection/poisoning attacks).Systems normally lookup any name (including domain names) using the
hostsfile first (if present), followed by DNS. However, thensswitch.conffile (typically in /etc) controls this order (normally hosts: file dns), allowing the order to be changed or the file value to be deleted entirely depending on local needs. Unless the BIND administrator controls this file and knows its values, it is unsafe to assume that localhost is forward-mapped correctly.As a reminder to users that unnecessary queries for localhost form a non-trivial volume of DNS queries on the public network, which affects DNS performance for all users.
Users may, however, elect at their discretion not to implement this file since, depending on the operational environment, it may not be essential.
The BIND 9 distribution file localhost-forward.db format is shown for
completeness and provides for both IPv4 and IPv6 localhost resolution. The zone
(domain) name is localhost.
$TTL 3h
localhost. SOA localhost. nobody.localhost. 42 1d 12h 1w 3h
NS localhost.
A 127.0.0.1
AAAA ::1
Note
Readers of a certain age or disposition may note the reference in this file to the late, lamented Douglas Noel Adams.
3.1.5. localhost Reverse-Mapped Zone File
This zone file allows any query requesting the name associated with the
loopback IP (127.0.0.1). This file is required to prevent unnecessary queries
from reaching the public DNS hierarchy. The BIND 9 distribution file
localhost.rev is shown for completeness:
$TTL 1D
@ IN SOA localhost. root.localhost. (
2007091701 ; serial
30800 ; refresh
7200 ; retry
604800 ; expire
300 ) ; minimum
IN NS localhost.
1 IN PTR localhost.
3.2. Authoritative Name Servers
These provide authoritative answers to user queries for the zones they support: for instance, the zone data describing the domain name example.com. An authoritative name server may support one or many zones.
Each zone may be defined as either a primary or a secondary. A primary zone reads its zone data directly from a file system. A secondary zone obtains its zone data from the primary zone using a process called zone transfer. Both the primary and the secondary zones provide authoritative data for their zone; there is no difference in the answer to a query from a primary or a secondary zone. An authoritative name server may support any combination of primary and secondary zones.
Note
The terms primary and secondary do not imply any access priority. Resolvers (name servers that provide the complete answers to user queries) are not aware of (and cannot find out) whether an authoritative answer comes from the primary or secondary name server. Instead, the resolver uses the list of authoritative servers for the zone (there must be at least two) and maintains a Round Trip Time (RTT) - the time taken to respond to the query - for each server in the list. The resolver uses the lowest-value server (the fastest) as its preferred server for the zone and continues to do so until its RTT becomes higher than the next slowest in its list, at which time that one becomes the preferred server.
For reasons of backward compatibility BIND 9 treats “primary” and “master” as synonyms, as well as “secondary” and “slave.”
The following diagram shows the relationship between the primary and secondary name servers. The text below explains the process in detail.
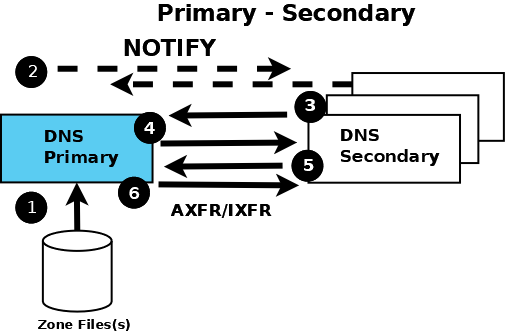
Authoritative Primary and Secondary Name Servers
The numbers in parentheses in the following text refer to the numbered items in the diagram above.
The authoritative primary name server always loads (or reloads) its zone files from (1) a local or networked filestore.
The authoritative secondary name server always loads its zone data from a primary via a zone transfer operation. Zone transfer may use AXFR (complete zone transfer) or IXFR (incremental zone transfer), but only if both primary and secondary name servers support the service. The zone transfer process (either AXFR or IXFR) works as follows:
The secondary name server for the zone reads (3 and 4) the SOA RR periodically. The interval is defined by the refresh parameter of the Start of Authority (SOA) RR.
The secondary compares the serial number parameter of the SOA RR received from the primary with the serial number in the SOA RR of its current zone data.
If the received serial number is arithmetically greater (higher) than the current one, the secondary initiates a zone transfer (5) using AXFR or IXFR (depending on the primary and secondary configuration), using TCP over port 53 (6).
The typically recommended zone refresh times for the SOA RR (the time interval when the secondary reads or polls the primary for the zone SOA RR) are multiples of hours to reduce traffic loads. Worst-case zone change propagation can therefore take extended periods.
The optional NOTIFY (RFC 1996) feature (2) is automatically configured; use the
notifystatement to turn off the feature. Whenever the primary loads or reloads a zone, it sends a NOTIFY message to the configured secondary (or secondaries) and may optionally be configured to send the NOTIFY message to other hosts using thealso-notifystatement. The NOTIFY message simply indicates to the secondary that the primary has loaded or reloaded the zone. On receipt of the NOTIFY message, the secondary respons to indicate it has received the NOTIFY and immediately reads the SOA RR from the primary (as described in section 2 a. above). If the zone file has changed, propagation is practically immediate.
The authoritative samples all use NOTIFY but identify the statements used, so that they can be removed if not required.
3.3. Resolver (Caching Name Servers)
Resolvers handle recursive user queries and provide complete answers; that is, they issue one or more iterative queries to the DNS hierarchy. Having obtained a complete answer (or an error), a resolver passes the answer to the user and places it in its cache. Subsequent user requests for the same query will be answered from the resolver’s cache until the TTL of the cached answer has expired, when it will be flushed from the cache; the next user query that requests the same information results in a new series of queries to the DNS hierarchy.
Resolvers are frequently referred to by a bewildering variety of names, including caching name servers, recursive name servers, forwarding resolvers, area resolvers, and full-service resolvers.
The following diagram shows how resolvers can function in a typical networked environment:
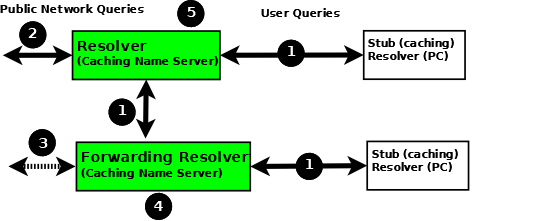
Resolver and Forwarding Resolver
End-user systems are all distributed with a local stub resolver as a standard feature. Today, the majority of stub resolvers also provide a local cache service to speed up user response times.
A stub resolver has limited functionality; specifically, it cannot follow referrals. When a stub resolver receives a request for a name from a local program, such as a browser, and the answer is not in its local cache, it sends a recursive user query (1) to a locally configured resolver (5), which may have the answer available in its cache. If it does not, it issues iterative queries (2) to the DNS hierarchy to obtain the answer. The resolver to which the local system sends the user query is configured, for Linux and Unix hosts, in
/etc/resolv.conf; for Windows users it is configured or changed via the Control Panel or Settings interface.Alternatively, the user query can be sent to a forwarding resolver (4). Forwarding resolvers on first glance look fairly pointless, since they appear to be acting as a simple pass-though and, like the stub resolver, require a full-service resolver (5). However, forwarding resolvers can be very powerful additions to a network for the following reasons:
Cost and Performance. Each recursive user query (1) at the forwarding resolver (4) results in two messages - the query and its answer. The resolver (5) may have to issue three, four, or more query pairs (2) to get the required answer. Traffic is reduced dramatically, increasing performance or reducing cost (if the link is tariffed). Additionally, since the forwarding resolver is typically shared across multiple hosts, its cache is more likely to contain answers, again improving user performance.
Network Maintenance. Forwarding resolvers (4) can be used to ease the burden of local administration by providing a single point at which changes to remote name servers can be managed, rather than having to update all hosts. Thus, all hosts in a particular network section or area can be configured to point to a forwarding resolver, which can be configured to stream DNS traffic as desired and changed over time with minimal effort.
Sanitizing Traffic. Especially in larger private networks it may be sensible to stream DNS traffic using a forwarding resolver structure. The forwarding resolver (4) may be configured, for example, to handle all in-domain traffic (relatively safe) and forward all external traffic to a hardened resolver (5).
Stealth Networks. Forwarding resolvers are extensively used in stealth or split networks.
Forwarding resolvers (4) can be configured to forward all traffic to a resolver (5), or to only forward selective traffic (5) while directly resolving other traffic (3).
Attention
While the diagram above shows recursive user queries arriving via interface (1), there is nothing to stop them from arriving via interface (2) via the public network. If no limits are placed on the source IPs that can send such queries, the resolver is termed an open resolver. Indeed, when the world was young this was the way things worked on the Internet. Much has changed and what seems to be a friendly, generous action can be used by rogue actors to cause all kinds of problems including Denial of Service (DoS) attacks. Resolvers should always be configured to limit the IP addresses that can use their services. BIND 9 provides a number of statements and blocks to simplify defining these IP limits and configuring a closed resolver. The resolver samples given here all configure closed resolvers using a variety of techniques.
3.3.1. Additional Zone Files
3.3.1.1. Root Servers (Hint) Zone File
Resolvers (although not necessarily forwarding resolvers) need to access the
DNS hierarchy. To do this, they need to know the addresses (IPv4 and/or IPv6)
of the 13 root servers. This is done by the provision of a
root server zone file, which is contained in the standard BIND 9 distribution
as the file named.root (normally found in /etc/namedb or
/usr/local/namedb). This file may also be obtained from the IANA website
(https://www.iana.org/domains/root/files).
Note
Many distributions rename this file for historical reasons. Consult the appropriate distribution documentation for the actual file name.
The hint zone file is referenced using the type hint statement and
a zone (domain) name of “.” (the generally silent dot).
Note
The root server IP addresses have been stable for a number of years and are likely to remain stable for the near future. BIND 9 has a root-server list in its executable such that even if this file is omitted, out-of-date, or corrupt BIND 9 can still function. For this reason, many sample configurations omit the hints file. All the samples given here include the hints file primarily as a reminder of the functionality of the configuration, rather than as an absolute necessity.
3.3.1.2. Private IP Reverse Map Zone Files
Resolvers are configured to send iterative queries to the public DNS hierarchy when the information requested is not in their cache or not defined in any local zone file. Many networks make extensive use of private IP addresses (defined by RFC 1918, RFC 2193, RFC 5737, and RFC 6598). By their nature these IP addresses are forward-mapped in various user zone files. However, certain applications may issue reverse map queries (mapping an IP address to a name). If the private IP addresses are not defined in one or more reverse-mapped zone file(s), the resolver sends them to the DNS hierarchy where they are simply useless traffic, slowing down DNS responses for all users.
Private IP addresses may be defined using standard reverse-mapping
techniques or using the
empty-zones-enable statement. By
default this statement is set to empty-zones-enable yes; and thus automatically prevents
unnecessary DNS traffic by sending an NXDOMAIN error response (indicating the
name does not exist) to any request. However, some applications may require a
genuine answer to such reverse-mapped requests or they will fail to function.
Mail systems in particular perform reverse DNS queries as a first-line spam
check; in this case a reverse-mapped zone file is essential. The sample
configuration files given here for both the resolver and the forwarding
resolver provide a reverse-mapping zone file for the private IP address
192.168.254.4, which is the mail server address in the base zone
file, as an illustration of the reverse-map technique. The
file is named 192.168.254.rev and has a zone name of
254.168.192.in-addr.arpa.
; reverse map zone file for 192.168.254.4 only
$TTL 2d ; 172800 seconds
$ORIGIN 254.168.192.IN-ADDR.ARPA.
@ IN SOA ns1.example.com. hostmaster.example.com. (
2003080800 ; serial number
3h ; refresh
15m ; update retry
3w ; expiry
3h ; nx = nxdomain ttl
)
; only one NS is required for this local file
; and is an out of zone name
IN NS ns1.example.com.
; other IP addresses can be added as required
; this maps 192.168.254.4 as shown
4 IN PTR mail.example.com. ; fully qualified domain name (FQDN)
3.3.2. Resolver Configuration
The resolver provides recursive query support to a defined set of IP addresses. It is therefore a closed resolver and cannot be used in wider network attacks.
// resolver named.conf file
// Two corporate subnets we wish to allow queries from
// defined in an acl clause
acl corpnets {
192.168.4.0/24;
192.168.7.0/24;
};
// options clause defining the server-wide properties
options {
// all relative paths use this directory as a base
directory "/var";
// version statement for security to avoid hacking known weaknesses
// if the real version number is revealed
version "not currently available";
// this is the default
recursion yes;
// recursive queries only allowed from these ips
// and references the acl clause
allow-query { corpnets; };
// this ensures that any reverse map for private IPs
// not defined in a zone file will *not* be passed to the public network
// it is the default value
empty-zones-enable yes;
};
// logging clause
// log to /var/log/named/example.log all events from info UP in severity (no debug)
// uses 3 files in rotation swaps files when size reaches 250K
// failure messages that occur before logging is established are
// in syslog (/var/log/messages)
//
logging {
channel example_log {
// uses a relative path name and the directory statement to
// expand to /var/log/named/example.log
file "log/named/example.log" versions 3 size 250k;
// only log info and up messages - all others discarded
severity info;
};
category default {
example_log;
};
};
// zone file for the root servers
// discretionary zone (see root server discussion above)
zone "." {
type hint;
file "named.root";
};
// zone file for the localhost forward map
// discretionary zone depending on hosts file (see discussion)
zone "localhost" {
type primary;
file "masters/localhost-forward.db";
notify no;
};
// zone file for the loopback address
// necessary zone
zone "0.0.127.in-addr.arpa" {
type primary;
file "localhost.rev";
notify no;
};
// zone file for local IP reverse map
// discretionary file depending on requirements
zone "254.168.192.in-addr.arpa" {
type primary;
file "192.168.254.rev";
notify no;
};
The zone and acl blocks, and the
allow-query, empty-zones-enable,
file, notify, recursion, and
type statements are described in detail in the appropriate
sections.
As a reminder, the configuration of this resolver does not access the DNS hierarchy (does not use the public network) for any recursive query for which:
The answer is already in the cache.
The domain name is localhost (zone localhost).
Is a reverse-map query for 127.0.0.1 (zone 0.0.127.in-addr.arpa).
Is a reverse-map query for 192.168.254/24 (zone 254.168.192.in-addr.arpa).
Is a reverse-map query for any local IP (
empty-zones-enablestatement).
All other recursive queries will result in access to the DNS hierarchy to resolve the query.
3.3.3. Forwarding Resolver Configuration
This forwarding resolver configuration forwards all recursive queries, other than those for the defined zones and those for which the answer is already in its cache, to a full-service resolver at the IP address 192.168.250.3, with an alternative at 192.168.230.27. The forwarding resolver will cache all responses from these servers. The configuration is closed, in that it defines those IPs from which it will accept recursive queries.
A second configuration in which selective forwarding occurs is also provided.
// forwarding named.conf file
// Two corporate subnets we wish to allow queries from
// defined in an acl clause
acl corpnets {
192.168.4.0/24;
192.168.7.0/24;
};
// options clause defining the server-wide properties
options {
// all relative paths use this directory as a base
directory "/var";
// version statement for security to avoid hacking known weaknesses
// if the real version number is revealed
version "not currently available";
// this is the default
recursion yes;
// recursive queries only allowed from these ips
// and references the acl clause
allow-query { corpnets; };
// this ensures that any reverse map for private IPs
// not defined in a zone file will *not* be passed to the public network
// it is the default value
empty-zones-enable yes;
// this defines the addresses of the resolvers to which queries will be forwarded
forwarders {
192.168.250.3;
192.168.230.27;
};
// indicates all queries will be forwarded other than for defined zones
forward only;
};
// logging clause
// log to /var/log/named/example.log all events from info UP in severity (no debug)
// uses 3 files in rotation swaps files when size reaches 250K
// failure messages that occur before logging is established are
// in syslog (/var/log/messages)
//
logging {
channel example_log {
// uses a relative path name and the directory statement to
// expand to /var/log/named/example.log
file "log/named/example.log" versions 3 size 250k;
// only log info and up messages - all others discarded
severity info;
};
category default {
example_log;
};
};
// hints zone file is not required
// zone file for the localhost forward map
// discretionary zone depending on hosts file (see discussion)
zone "localhost" {
type primary;
file "masters/localhost-forward.db";
notify no;
};
// zone file for the loopback address
// necessary zone
zone "0.0.127.in-addr.arpa" {
type primary;
file "localhost.rev";
notify no;
};
// zone file for local IP reverse map
// discretionary file depending on requirements
zone "254.168.192.in-addr.arpa" {
type primary;
file "192.168.254.rev";
notify no;
};
The zone and acl blocks, and the
allow-query, empty-zones-enable,
file, forward, forwarders,
notify, recursion, and type
statements are described in detail in the appropriate sections.
As a reminder, the configuration of this forwarding resolver does not forward any recursive query for which:
The answer is already in the cache.
The domain name is localhost (zone localhost).
Is a reverse-map query for 127.0.0.1 (zone 0.0.127.in-addr.arpa).
Is a reverse-map query for 192.168.254/24 (zone 254.168.192.in-addr.arpa).
Is a reverse-map query for any local IP (
empty-zones-enablestatement).
All other recursive queries will be forwarded to resolve the query.
3.3.4. Selective Forwarding Resolver Configuration
This forwarding resolver configuration only forwards recursive queries for the zone example.com to the resolvers at 192.168.250.3 and 192.168.230.27. All other recursive queries, other than those for the defined zones and those for which the answer is already in its cache, are handled by this resolver. The forwarding resolver will cache all responses from both the public network and from the forwarded resolvers. The configuration is closed, in that it defines those IPs from which it will accept recursive queries.
// selective forwarding named.conf file
// Two corporate subnets we wish to allow queries from
// defined in an acl clause
acl corpnets {
192.168.4.0/24;
192.168.7.0/24;
};
// options clause defining the server-wide properties
options {
// all relative paths use this directory as a base
directory "/var";
// version statement for security to avoid hacking known weaknesses
// if the real version number is revealed
version "not currently available";
// this is the default
recursion yes;
// recursive queries only allowed from these ips
// and references the acl clause
allow-query { corpnets; };
// this ensures that any reverse map for private IPs
// not defined in a zone file will *not* be passed to the public network
// it is the default value
empty-zones-enable yes;
// forwarding is not global but selective by zone in this configuration
};
// logging clause
// log to /var/log/named/example.log all events from info UP in severity (no debug)
// uses 3 files in rotation swaps files when size reaches 250K
// failure messages that occur before logging is established are
// in syslog (/var/log/messages)
//
logging {
channel example_log {
// uses a relative path name and the directory statement to
// expand to /var/log/named/example.log
file "log/named/example.log" versions 3 size 250k;
// only log info and up messages - all others discarded
severity info;
};
category default {
example_log;
};
};
// zone file for the root servers
// discretionary zone (see root server discussion above)
zone "." {
type hint;
file "named.root";
};
// zone file for the localhost forward map
// discretionary zone depending on hosts file (see discussion)
zone "localhost" {
type primary;
file "masters/localhost-forward.db";
notify no;
};
// zone file for the loopback address
// necessary zone
zone "0.0.127.in-addr.arpa" {
type primary;
file "localhost.rev";
notify no;
};
// zone file for local IP reverse map
// discretionary file depending on requirements
zone "254.168.192.in-addr.arpa" {
type primary;
file "192.168.254.rev";
notify no;
};
// zone file forwarded example.com
zone "example.com" {
type forward;
// this defines the addresses of the resolvers to
// which queries for this zone will be forwarded
forwarders {
192.168.250.3;
192.168.230.27;
};
// indicates all queries for this zone will be forwarded
forward only;
};
The zone and acl blocks, and the
allow-query, empty-zones-enable,
file, forward, forwarders,
notify, recursion, and type
statements are described in detail in the appropriate sections.
As a reminder, the configuration of this resolver does not access the DNS hierarchy (does not use the public network) for any recursive query for which:
The answer is already in the cache.
The domain name is localhost (zone localhost).
Is a reverse-map query for 127.0.0.1 (zone 0.0.127.in-addr.arpa).
Is a reverse-map query for 192.168.254/24 (zone 254.168.192.in-addr.arpa).
Is a reverse-map query for any local IP (empty-zones-enable statement).
Is a query for the domain name example.com, in which case it will be forwarded to either 192.168.250.3 or 192.168.230.27 (zone example.com).
All other recursive queries will result in access to the DNS hierarchy to resolve the query.
3.4. Load Balancing
A primitive form of load balancing can be achieved in the DNS by using multiple resource records (RRs) in a zone file (such as multiple A records) for one name.
For example, assuming three HTTP servers with network addresses of 10.0.0.1, 10.0.0.2, and 10.0.0.3, a set of records such as the following means that clients will connect to each machine one-third of the time:
Name |
TTL |
CLASS |
TYPE |
Resource Record (RR) Data |
www |
600 |
IN |
A |
10.0.0.1 |
600 |
IN |
A |
10.0.0.2 |
|
600 |
IN |
A |
10.0.0.3 |
When a resolver queries for these records, BIND rotates them and responds to the query with the records in a random order. In the example above, clients randomly receive records in the order 1, 2, 3; 2, 3, 1; and 3, 1, 2. Most clients use the first record returned and discard the rest.
For more detail on ordering responses, refer to the
rrset-order statement in the
options block.
3.5. Zone File
This section, largely borrowed from RFC 1034, describes the concept of a Resource Record (RR) and explains how to use them.
3.5.1. Resource Records
A domain name identifies a node in the DNS tree namespace. Each node has a set of resource
information, which may be empty. The set of resource information
associated with a particular name is composed of separate RRs. The order
of RRs in a set is not significant and need not be preserved by name
servers, resolvers, or other parts of the DNS. However, sorting of
multiple RRs is permitted for optimization purposes: for example, to
specify that a particular nearby server be tried first. See
sortlist and RRset Ordering.
The components of a Resource Record are:
- owner name
The domain name where the RR is found.
- RR type
An encoded 16-bit value that specifies the type of the resource record. For a list of types of valid RRs, including those that have been obsoleted, please refer to https://www.iana.org/assignments/dns-parameters/dns-parameters.xhtml#dns-parameters-4.
- TTL
The time-to-live of the RR. This field is a 32-bit integer in units of seconds, and is primarily used by resolvers when they cache RRs. The TTL describes how long a RR can be cached before it should be discarded.
- class
An encoded 16-bit value that identifies a protocol family or an instance of a protocol.
- RDATA
The resource data. The format of the data is type- and sometimes class-specific.
The following classes of resource records are currently valid in the DNS:
- IN
The Internet. The only widely class used today.
- CH
Chaosnet, a LAN protocol created at MIT in the mid-1970s. It was rarely used for its historical purpose, but was reused for BIND’s built-in server information zones, e.g., version.bind.
- HS
Hesiod, an information service developed by MIT’s Project Athena. It was used to share information about various systems databases, such as users, groups, printers, etc.
The owner name is often implicit, rather than forming an integral part of the RR. For example, many name servers internally form tree or hash structures for the name space, and chain RRs off nodes. The remaining RR parts are the fixed header (type, class, TTL), which is consistent for all RRs, and a variable part (RDATA) that fits the needs of the resource being described.
The TTL field is a time limit on how long an RR can be kept in a cache. This limit does not apply to authoritative data in zones; that also times out, but follows the refreshing policies for the zone. The TTL is assigned by the administrator for the zone where the data originates. While short TTLs can be used to minimize caching, and a zero TTL prohibits caching, the realities of Internet performance suggest that these times should be on the order of days for the typical host. If a change is anticipated, the TTL can be reduced prior to the change to minimize inconsistency, and then increased back to its former value following the change.
The data in the RDATA section of RRs is carried as a combination of binary strings and domain names. The domain names are frequently used as “pointers” to other data in the DNS.
3.5.1.1. Textual Expression of RRs
RRs are represented in binary form in the packets of the DNS protocol, and are usually represented in highly encoded form when stored in a name server or resolver. In the examples provided in RFC 1034, a style similar to that used in primary files was employed in order to show the contents of RRs. In this format, most RRs are shown on a single line, although continuation lines are possible using parentheses.
The start of the line gives the owner of the RR. If a line begins with a blank, then the owner is assumed to be the same as that of the previous RR. Blank lines are often included for readability.
Following the owner are listed the TTL, type, and class of the RR. Class and type use the mnemonics defined above, and TTL is an integer before the type field. To avoid ambiguity in parsing, type and class mnemonics are disjoint, TTLs are integers, and the type mnemonic is always last. The IN class and TTL values are often omitted from examples in the interest of clarity.
The resource data or RDATA section of the RR is given using knowledge of the typical representation for the data.
For example, the RRs carried in a message might be shown as:
ISI.EDU.
MX
10 VENERA.ISI.EDU.
MX
10 VAXA.ISI.EDU
VENERA.ISI.EDU
A
128.9.0.32
A
10.1.0.52
VAXA.ISI.EDU
A
10.2.0.27
A
128.9.0.33
The MX RRs have an RDATA section which consists of a 16-bit number followed by a domain name. The address RRs use a standard IP address format to contain a 32-bit Internet address.
The above example shows six RRs, with two RRs at each of three domain names.
Here is another possible example:
XX.LCS.MIT.EDU.
IN A
10.0.0.44
CH A
MIT.EDU. 2420
This shows two addresses for XX.LCS.MIT.EDU, each of a different class.
3.5.2. Discussion of MX Records
As described above, domain servers store information as a series of resource records, each of which contains a particular piece of information about a given domain name (which is usually, but not always, a host). The simplest way to think of an RR is as a typed pair of data, a domain name matched with a relevant datum and stored with some additional type information, to help systems determine when the RR is relevant.
MX records are used to control delivery of email. The data specified in the record is a priority and a domain name. The priority controls the order in which email delivery is attempted, with the lowest number first. If two priorities are the same, a server is chosen randomly. If no servers at a given priority are responding, the mail transport agent falls back to the next largest priority. Priority numbers do not have any absolute meaning; they are relevant only respective to other MX records for that domain name. The domain name given is the machine to which the mail is delivered. It must have an associated address record (A or AAAA); CNAME is not sufficient.
For a given domain, if there is both a CNAME record and an MX record, the MX record is in error and is ignored. Instead, the mail is delivered to the server specified in the MX record pointed to by the CNAME. For example:
example.com.
IN
MX
10
mail.example.com.
IN
MX
10
mail2.example.com.
IN
MX
20
mail.backup.org.
mail.example.com.
IN
A
10.0.0.1
mail2.example.com.
IN
A
10.0.0.2
Mail delivery is attempted to mail.example.com and mail2.example.com (in any order); if neither of those succeeds, delivery to mail.backup.org is attempted.
3.5.3. Setting TTLs
The time-to-live (TTL) of the RR field is a 32-bit integer represented in units of seconds, and is primarily used by resolvers when they cache RRs. The TTL describes how long an RR can be cached before it should be discarded. The following three types of TTLs are currently used in a zone file.
- SOA minimum
The last field in the SOA is the negative caching TTL. This controls how long other servers cache no-such-domain (NXDOMAIN) responses from this server. Further details can be found in RFC 2308.
The maximum time for negative caching is 3 hours (3h).
- $TTL
The $TTL directive at the top of the zone file (before the SOA) gives a default TTL for every RR without a specific TTL set.
- RR TTLs
Each RR can have a TTL as the second field in the RR, which controls how long other servers can cache it.
All of these TTLs default to units of seconds, though units can be explicitly specified: for example, 1h30m.
3.5.4. Inverse Mapping in IPv4
Reverse name resolution (that is, translation from IP address to name) is achieved by means of the in-addr.arpa domain and PTR records. Entries in the in-addr.arpa domain are made in least-to-most significant order, read left to right. This is the opposite order to the way IP addresses are usually written. Thus, a machine with an IP address of 10.1.2.3 would have a corresponding in-addr.arpa name of 3.2.1.10.in-addr.arpa. This name should have a PTR resource record whose data field is the name of the machine or, optionally, multiple PTR records if the machine has more than one name. For example, in the example.com domain:
$ORIGIN
2.1.10.in-addr.arpa
3
IN PTR foo.example.com.
Note
The $ORIGIN line in this example is only to provide context; it does not necessarily appear in the actual usage. It is only used here to indicate that the example is relative to the listed origin.
3.5.5. Other Zone File Directives
The DNS “master file” format was initially defined in RFC 1035 and has subsequently been extended. While the format itself is class-independent, all records in a zone file must be of the same class.
Master file directives include $ORIGIN, $INCLUDE, and $TTL.
3.5.5.1. The @ (at-sign)
When used in the label (or name) field, the asperand or at-sign (@) symbol represents the current origin. At the start of the zone file, it is the <zone_name>, followed by a trailing dot (.).
3.5.5.2. The $ORIGIN Directive
Syntax: $ORIGIN domain-name [comment]
$ORIGIN sets the domain name that is appended to any
unqualified records. When a zone is first read, there is an implicit
$ORIGIN <zone_name>.; note the trailing dot. The
current $ORIGIN is appended to the domain specified in the
$ORIGIN argument if it is not absolute.
$ORIGIN example.com.
WWW CNAME MAIN-SERVER
is equivalent to
WWW.EXAMPLE.COM. CNAME MAIN-SERVER.EXAMPLE.COM.
3.5.5.3. The $INCLUDE Directive
Syntax: $INCLUDE filename [origin] [comment]
This reads and processes the file filename as if it were included in the
file at this point. The filename can be an absolute path, or a relative
path. In the latter case it is read from named’s working directory. If
origin is specified, the file is processed with $ORIGIN set to that
value; otherwise, the current $ORIGIN is used.
The origin and the current domain name revert to the values they had prior to the $INCLUDE once the file has been read.
3.5.5.4. The $TTL Directive
Syntax: $TTL default-ttl [comment]
This sets the default Time-To-Live (TTL) for subsequent records with undefined TTLs. Valid TTLs are of the range 0-2147483647 seconds.
$TTL is defined in RFC 2308.
3.5.6. BIND Primary File Extension: the $GENERATE Directive
Syntax: $GENERATE range owner [ttl] [class] type rdata [comment]
$GENERATE is used to create a series of resource records that only differ from each other by an iterator.
- range
This can be one of two forms: start-stop or start-stop/step. If the first form is used, then step is set to 1. “start”, “stop”, and “step” must be positive integers between 0 and (2^31)-1. “start” must not be larger than “stop”.
- owner
This describes the owner name of the resource records to be created.
The owner string may include one or more $ (dollar sign) symbols, which will be replaced with the iterator value when generating records; see below for details.
- ttl
This specifies the time-to-live of the generated records. If not specified, this is inherited using the normal TTL inheritance rules.
class and ttl can be entered in either order.
- class
This specifies the class of the generated records. This must match the zone class if it is specified.
class and ttl can be entered in either order.
- type
This can be any valid type.
- rdata
This is a string containing the RDATA of the resource record to be created. As with owner, the rdata string may include one or more $ symbols, which are replaced with the iterator value. rdata may be quoted if there are spaces in the string; the quotation marks do not appear in the generated record.
Any single $ (dollar sign) symbols within the owner or rdata strings are replaced by the iterator value. To get a $ in the output, escape the $ using a backslash \, e.g.,
\$. (For compatibility with earlier versions, $$ is also recognized as indicating a literal $ in the output.)The $ may optionally be followed by modifiers which change the offset from the iterator, field width, and base. Modifiers are introduced by a { (left brace) immediately following the $, as in ${offset[,width[,base]]}. For example, ${-20,3,d} subtracts 20 from the current value and prints the result as a decimal in a zero-padded field of width 3. Available output forms are decimal (d), octal (o), hexadecimal (x or X for uppercase), and nibble (n or N for uppercase). The modfiier cannot contain whitespace or newlines.
The default modifier is ${0,0,d}. If the owner is not absolute, the current $ORIGIN is appended to the name.
In nibble mode, the value is treated as if it were a reversed hexadecimal string, with each hexadecimal digit as a separate label. The width field includes the label separator.
Examples:
$GENERATE can be used to easily generate the sets of records required to support sub-/24 reverse delegations described in RFC 2317:
$ORIGIN 0.0.192.IN-ADDR.ARPA.
$GENERATE 1-2 @ NS SERVER$.EXAMPLE.
$GENERATE 1-127 $ CNAME $.0
is equivalent to
0.0.0.192.IN-ADDR.ARPA. NS SERVER1.EXAMPLE.
0.0.0.192.IN-ADDR.ARPA. NS SERVER2.EXAMPLE.
1.0.0.192.IN-ADDR.ARPA. CNAME 1.0.0.0.192.IN-ADDR.ARPA.
2.0.0.192.IN-ADDR.ARPA. CNAME 2.0.0.0.192.IN-ADDR.ARPA.
...
127.0.0.192.IN-ADDR.ARPA. CNAME 127.0.0.0.192.IN-ADDR.ARPA.
This example creates a set of A and MX records. Note the MX’s rdata is a quoted string; the quotes are stripped when $GENERATE is processed:
$ORIGIN EXAMPLE.
$GENERATE 1-127 HOST-$ A 1.2.3.$
$GENERATE 1-127 HOST-$ MX "0 ."
is equivalent to
HOST-1.EXAMPLE. A 1.2.3.1
HOST-1.EXAMPLE. MX 0 .
HOST-2.EXAMPLE. A 1.2.3.2
HOST-2.EXAMPLE. MX 0 .
HOST-3.EXAMPLE. A 1.2.3.3
HOST-3.EXAMPLE. MX 0 .
...
HOST-127.EXAMPLE. A 1.2.3.127
HOST-127.EXAMPLE. MX 0 .
This example generates A and AAAA records using modifiers; the AAAA owner names are generated using nibble mode:
$ORIGIN EXAMPLE.
$GENERATE 0-2 HOST-${0,4,d} A 1.2.3.${1,0,d}
$GENERATE 1024-1026 ${0,3,n} AAAA 2001:db8::${0,4,x}
is equivalent to:
- ::
HOST-0000.EXAMPLE. A 1.2.3.1 HOST-0001.EXAMPLE. A 1.2.3.2 HOST-0002.EXAMPLE. A 1.2.3.3 0.0.4.EXAMPLE. AAAA 2001:db8::400 1.0.4.EXAMPLE. AAAA 2001:db8::401 2.0.4.EXAMPLE. AAAA 2001:db8::402
The $GENERATE directive is a BIND extension and not part of the standard zone file format.
3.5.7. Additional File Formats
In addition to the standard text format, BIND 9 supports the ability to read or dump to zone files in other formats.
The raw format is a binary representation of zone data in a manner similar to that used in zone transfers. Since it does not require parsing text, load time is significantly reduced.
For a primary server, a zone file in raw format is expected
to be generated from a text zone file by the named-compilezone command.
For a secondary server or a dynamic zone, the zone file is automatically
generated when named dumps the zone contents after zone transfer or
when applying prior updates, if one of these formats is specified by the
masterfile-format option.
If a zone file in raw format needs manual modification, it first must
be converted to text format by the named-compilezone command,
then converted back after editing. For example:
named-compilezone -f raw -F text -o zonefile.text <origin> zonefile.raw
[edit zonefile.text]
named-compilezone -f text -F raw -o zonefile.raw <origin> zonefile.text